ElasticSearch란?
“루씬(Lucene)이라는 검색 라이브러리를 기반으로 검색 기능을 제공하는 오픈 소스 검색 엔진이다."
-
아파치 루씬 기반 아파치 루씬 은 자바로 개발된 검색 서비스용 라이브러리. 루씬은 전문 텍스트 검색(Full text search)에 특화되어 있어 문서가 색인될 때부터 검색 가능해질 때까지의 대기시간이 매우 짧다는 장점이 있다.
-
Restful API REST API 형태로 조작할 수 있다. 검색 및 분석 결과를 API 형태로 제공한다. 어플리케이션에서 쉽게 활용할 수 있는 장점이 있다.
-
JSON 기반 JSON 형으로 모든 요청 및 응답 문서를 표현한다. 덕분에 텍스트, 숫자, 위치 기반 정보 등 정형, 비정형 데이터를 대상으로 분석 및 검색이 가능하다.
-
분산 시스템 클러스터 기반이기에 서버 확장이 가능하고, 확장된 서버에 데이터를 분산하여 병렬처리가 가능하기때문에 검색 대상의 용량이 크더라도 빠르게 분석 및 검색이 가능하다.
클러스터와 노드
-
클러스터: 여러 대의 컴퓨터 혹은 구성 요소들을 논리적으로 결합하여 전체를 하나의 컴퓨터, 하나의 구성 요소처럼 사용할 수 있게 해주는 기술
-
노드: 클러스터를 구성하는 하나하나의 프로세스
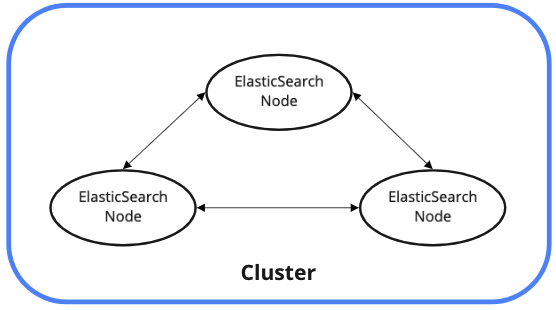
클러스터를 구성하고있는 노드 중 어느 노드에 요청해도 동일한 응답과 동작을 보장받을 수 있다.
단일 노드로도 클러스터를 구성할 수 있지만, 단일 노드로 클러스터를 구성했을 경우 해당 노드에 장애가 발생한다면 요청 불가 상태가 된다. 반면에 다수개의 노드로 클러스터를 구성하게되면, 하나의 노드에 장애가 발생해도 다른 노드에서 요청을 처리 할 수 있기에 안정적으로 운영이 가능하기때문에 단일 노드의 구성은 추천하지 않는다.
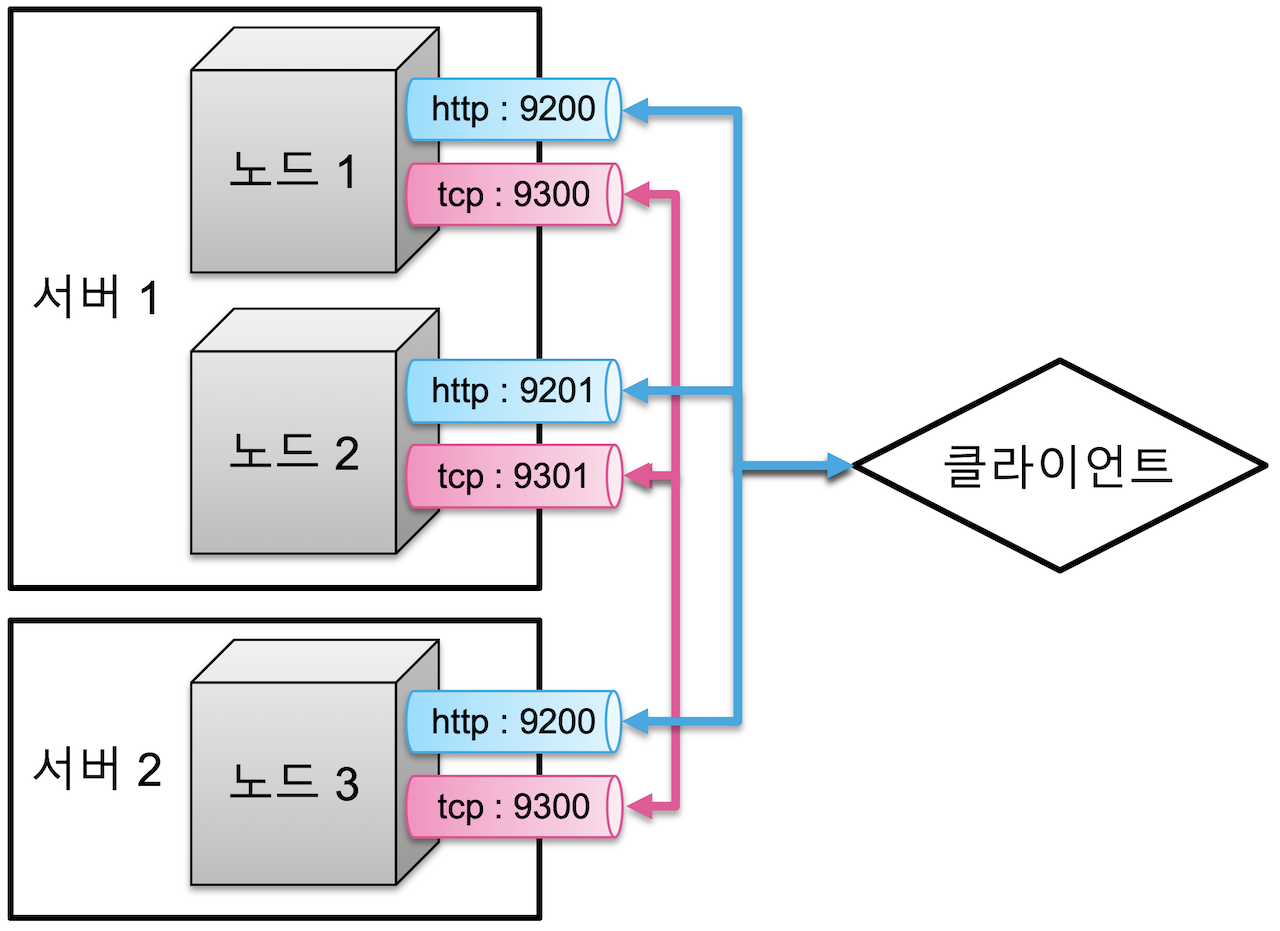
- 디스커버리: 노드가 처음 실행할 때 하나의 클러스터로 바인딩하는 과정

노드의 종류
-
마스터(Master-eligible)
- 클러스터 구성에서 중심이 되는 노드
- 클러스터 내의 노드의 상태, 성능 정보, 샤드 정보 등 메타데이터를 관리하면서 클러스터의 안정성을 확보하기 위해 필요한 작업을 수행한다.
- 반드시 한 대 이상으로 구성해야한다.
- 마스터 역할이 가능한 후보 노드와 실제 마스터 역할을 하는 노드로 구분된다.
- 마스터 후보 노드는 마스터 노드로부터 지속적으로 클러스터 운영에 필요한 데이터를 전달 받고, 마스터와 노드와 같은 메타 데이터를 유지한다.
- 마스터 노드 장애시 마스터 후보 노드 중 한대가 마스터 도의 역할을 수행하기때문에 중단 없이 서비스를 운영 가능하다.

-
데이터(Data)
-
사용자가 색인한 문서를 저장하고, 검색 요청을 처리해서 결과를 돌려주는 역할
-
자신이 요청을 직접 처리하거나 다른 데이터 노드에게 요청을 전달한다.

-
종류
- Content Data: 유저가 만든 콘텐츠를 수용하는 노드. CRUD, 검색 및 집계와 같은 작업을 가능하게한다.
- Hot Data: 시계열 데이터를 저장한다. Read/write가 빠르며 더 많은 하드웨어 리소스가 필요하기 때문에 고사양의 서버에 적합하다.
- Warm Data: 더 이상 업데이트가 되지 않지만 쿼리를 실행하는 인덱스를 저장한다. 오래된 데이터지만 활용하고 있는 데이터를 보관한다.
- Cold Data: 읽기 전용 인덱스를 저장한다.(자주 사용하지 않는 인덱스) 읽기 전용 데이터의 경우 클러스터의 저장공간을 최대 50% 절약 가능하다.
- Frozen Data: shared_cache 옵션만으로 마운트 된 검색 가능한 스냅샷을 저장한다. 스냅샷 데이터를 해당 노드에 저장하고 데이터를 검색 가능하도록 하는 노드이다.
-
-
인제스트(Ingest)
-
사용자가 색인하길 원하는 문서의 내용 중 변환이 필요한 부분을 사전에 처리하는 노드
-
데이터 노드에 저장하기 전 특정 필드의 값을 가공해야 할 경우 유용하다.
-
Logstash 와 비슷한 기능을 갖고있다.

-
-
코디네이트(Coordinate)
- 사용자의 요청을 데이터 노드로 전달하고, 다시 데이터 노드로부터 결과를 취합하는 노드
- 중간다리 역할을 한다.
- 문서를 저장하지 않는 데이터 노드라고 생각할 수 있다.

인덱스와 타입
인덱스(Index)
-
사용자의 데이터가 저장되는 논리적인 공간
-
RDBMS에 비교하자면 데이터베이스라고 볼 수 있다.
-
이름은 클러스터 내에서 유니크해야한다.
-
인덱스에 저장된 문서들은 데이터 노드들에 분산 저장된다.
타입(Type)
- 인덱스 안의 데이터를 유형별로 논리적으로 나눠 놓은 공간
- RDBMS에 비교하자면 테이블의 개념으로 볼 수 있다.
- 6.x 버전 이후로 하나의 인덱스에 하나의 타입만을 가질 수 있다. 큰 이슈가 없다면 _doc을 타입명으로 사용하게된다.
샤드와 세그먼트
ElasticSearch는 인덱스를 샤드로 나누고 나뉘어진 샤드에 세크먼트 단위로 문서를 저장한다.
샤드(Shard)
- 인덱스에 색인되는 문서들이 저장되는 논리적인 공간
- 장애 상황에서 유실되지않고, 서비스의 연속성을 유지하기 위해 프라이머리 샤드와 레플리카 샤드로 나눠서 관리한다.
- 프라이머리 샤드(Primary Shard)
- 인덱스를 최초로 생성하는 시점에 개수를 결정, 이후 변경 불가하다.
- 레플리카 샤드(Replica Shard)
- 프라이머리 샤드의 복제본
- 프라이머리 샤드가 저장된 노드와 다른 노드에 저장된다.
- 프라이머리 샤드와 동일한 문서를 가지고 있기 때문에 사용자의 검색 요청에도 응답 할 수 있어, 레플리카 샤드의 개수를 늘릴 경우 검색 요청에 대한 응답 속도를 높일 수 있다.
- 프라이머리 샤드(Primary Shard)
세그먼트(Segment)
- 샤드의 데이터들을 가지고 있는 물리적인 파일
- 하나의 샤드는 다수의 세그먼트로 구성되어있다.
- ElasticSearch에 데이터를 색인하면 ElasticSearch는 이것을 메모리에 모아두고 새로운 세그먼트를 디스크에 기록하여 검색을 리프레쉬하여 새로운 검색 가능한 세크먼트를 생성한다.
- 샤드에서 검색 시, 각 세그먼트를 검색하여 결과를 조합한 후 최종 결과를 해당 샤드의 결과로 리턴한다.
- 불변의 성질을 가지고 있기때문에 데이터가 업데이트되면, 실제로는 삭제되었다고 마크만하고 새로운 데이터를 가르키게 된고 삭제되었다고 마크된 데이터는 디스크에 남아있다 백그라운드에서 주기적/특정 임계치를 넘기면 더이상 필요없어진 데이터들을 정리하고 새로운 세그먼트로 병합한 후 세그먼트를 디스크에서 완전히 삭제하는 병합 과정을 거치게된다.
인덱스 세팅과 매핑
모든 인덱스는 settings, mappings 라는 두 개의 정보 단위를 가지고 있다.
settings
- 처음 인덱스를 정의하면 number_of_shards, number_of_replicas 와 같이 몇가지 정보들이 자동으로 생성된다.
- number_of_shards
- 프라이머리 샤드 수
- 인덱스를 처음 생성할 때 한번 지정하면 변경이 불가하다.
- 샤드의 수를 변경하려면 새로 인덱스를 정의하고 기존 인덱스의 데이터를 재색인 해야 한다.
- number_of_replicas
- 리플리카 샤드 수
- 다이나믹하게 변경이 가능하다.
- Refresh_interval
- ElasticSearch에서 세그먼트가 만들어지는 리프레시 타임을 설정하는 값
- default 값은 1s
- 다이나믹하게 변경이 가능하다.
- analyzer, tokenizer, filter
mappings
-
RDBMS와 비교하자면 스키마와 유사하다. ElasticSearch에 저장될 JSON 문서들이 어떤 키와 어떤 형태의 값을 가지고 있는지 즉, 사용자가 색인한 문서의 다양한 필드들을 적절한 타입으로 스키마를 정의하는 것이다.
-
미리 정의해 놓고 사용하는 정적 매핑(static mapping) 미리 정의하지 않은 상태에서 최초 색인된 문서를 바탕으로 ElasticSearch가 자동으로 매핑을 생성해주는 동적 매핑(dynamic mapping) 이 있다.
-
이미 만들어진 매핑에 필드를 추가하는 것은 가능하지만, 이미 만들어진 필드를 삭제하거나 필드의 타입 및 설정값을 변경한는 것은 불가능하다.
-
데이터 타입 종류
코어 데이터 타입 설명 종류 String 문자열 데이터 타입 text, keyword Numeric 숫자형 데이터 타입 Long, integer, short, byte, double, float, half_float, scaled_float Date 날짜형 데이터 타입 date Boolean Bool 데이터 타입 boolean Binary 바이너리 데이터 타입 binary Range 범주 데이터 타입 integer_range, float_range, long_range, double_range, date_range